A better way to discover things
(First appeared on the Canopy blog)
Do you remember the first time you saw something personalized to you on the internet? It was probably a long time ago. Things have changed a bit to say the least. You now have ads following you around, you have feeds of content sorted for maximum engagement, you find brand new creators every day, you have people and web search personalized to your location and preferences. Very little of your day to day digital experience is anonymous anymore.
Here’s a chart of how personalization and recommendations work today:
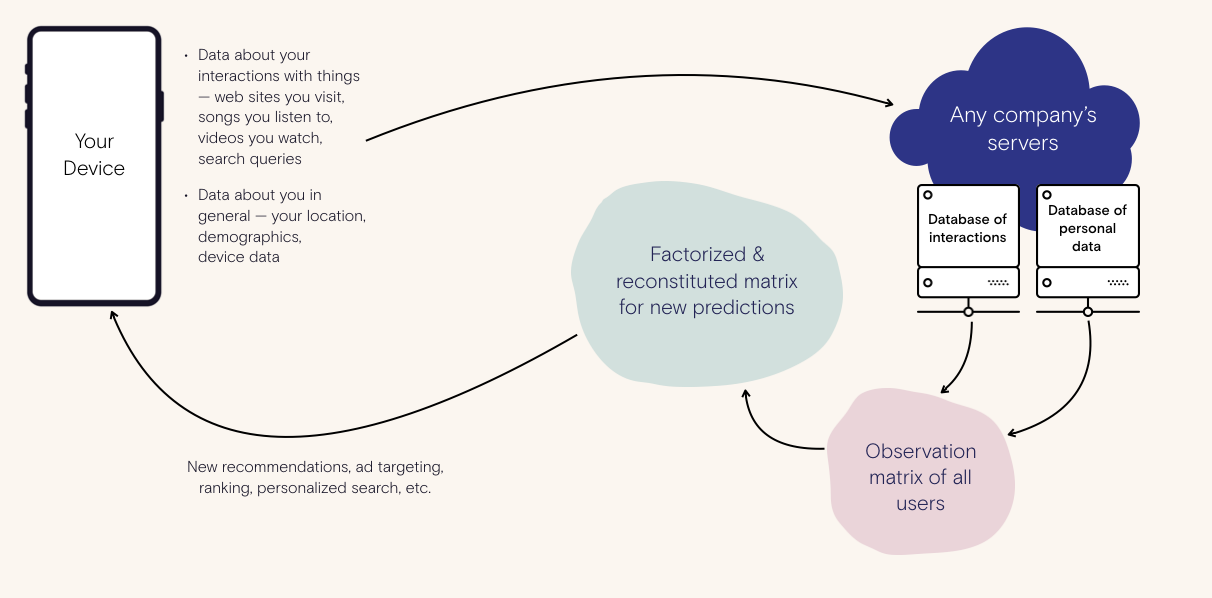
It all starts with platforms collecting as much personal and behavioral data as possible. This can be a combination of the things you’ve done -- songs you’ve listened to, or ads you’ve seen and clicked on or not clicked on, or the amount of time you’ve spent on a web site -- and personal data like your email, demographics, and location. All of this is sent from your device to someone else. In many cases your data is sent to multiple places. For example, a video streaming service may want their own copy of you, but a partner of theirs may want a copy for their own purposes.
If you collect enough behavioral data on a person, and send it to your server cluster, you’re able to build up a model of a person. That model is a computable summary that you can use to predict new things about someone. If you line up all the world’s behavioral data, you’ll see that there are obvious patterns: someone really into fashion also likes a certain kind of website, or people that like this YouTube video also watched this one. Or, more insidiously, people that see this type of content tend to stay longer on the app or site. This model uses the collected data of the rest of the world to get a better understanding of you. It can use simple counting, matrix factorization, or more recently, statistical machine learning approaches. The model is like a clone of you, that can guess what you’d do, what you’d like, what you’d buy, even for things you haven’t yet seen.
One of the many downsides of this approach is that the models are almost always a “black-box”: they are a series of tightly packed numbers that a computer can ask questions of, and get an ordered list of results back from, but rarely is it easy to explain why the results are in that order, or what bits of your behavioral data informed the answers.
Any current company’s stack we know of keeps both the raw data and the model data on their servers. Even if new regulations , privacy policies, or deletion features let people remove their data from a service, the models will likely stay around, and they can still predict the interaction and behavioral data with very high accuracy.
That’s the old way.
Here’s the Canopy way. Your personal devices are more powerful than ever. Your phone can likely do more than your computer, if you use one, and your phone is also more powerful than servers we did all that model-building on just a few years ago.
Our expectations of what our personal data is worth and what these algorithms are doing to us is shifting. At Canopy, we’ve been working on a new architecture for the past 18 months. It’s real now, and you can try it out if you join our beta for our first consumer experience. We want to run you through how it works, and show how it can put people back in the center of this process, while giving them even better discoveries than before.
Here’s how we do it:
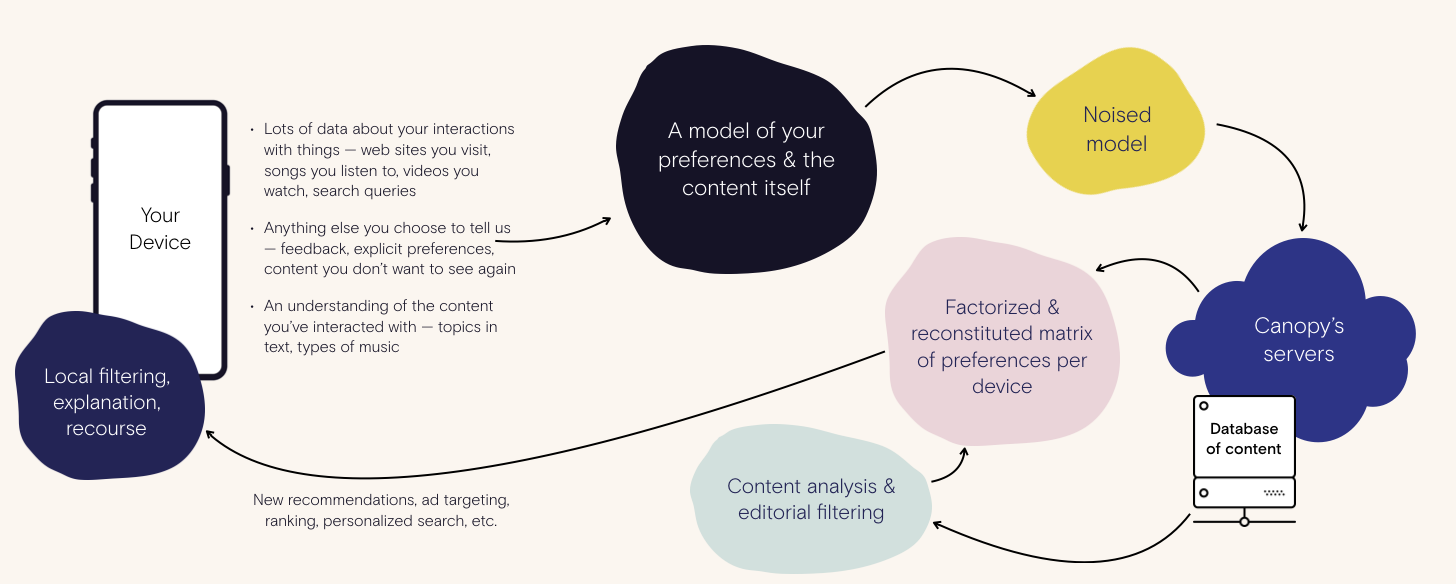
Many of us had built massively scaled recommendation, ad tech or analytics systems in past lives, and we all knew there were a few things we wished we could have accomplished. Three clear design goals came out of the Canopy stack from early on:
We wanted to keep interaction data private . We wanted our mediated discoveries to be explainable, and to give the person getting the discovery to have recourse to change what they see. We wanted a voice behind our discoveries -- a strong editorial stance across all types of media, that can give you context for your choices and also ensure we don’t blindly trust a purely algorithmic system that may work against you.
The first clear difference in our tech is that raw interaction and behavioral data stays on your device. In this model, Canopy never sees it, and neither would any content provider or partner we would work with. What we instead send over an encrypted connection to our server is a differentially private version of your personal interaction and behavior model. The local model of you that goes to Canopy never has a direct connection to the things you’ve interacted with, but instead represents an aggregate set of preferences of people like you. It’s a crucial difference for our approach: even in the worst case of the encryption failing, or our servers being hacked, no one could ever do anything with the private models because they do not represent any individual.
Apple has done a great job educating their users on this sort of technology -- but they are in the business of protecting your messages, photos and keyboard data, not the scarier interaction and behavioral data that informs so much of your internet experience. While some of the Canopy stack is inspired by and similar to some great work done by friends of ours at Apple and Google, our method focuses more on discovery than predicting variables, and has the added benefit on doing more with less data, allowing us to work across many types of devices and network connections across the world.
But your privacy in this model is just one core feature of the Canopy stack. We care just as deeply about recourse -- your ability to see why you’re seeing what you’re seeing, and change it. You should be in control of what you share and what you don’t share -- even if that data and information stays on your device.
At Canopy, we believe strongly that learning about content is more important than trying to amplify engagement. As an example of how context-less engagement systems could go wrong, a video recommender may find latent patterns in the idle history of the service’s users -- an average person might watch a sports clip then, due to further personalization via search, “up next” or social, find something unrelated, which feeds back into the recommender model as a correlation. What’s missing in this sort of “collaborative filtering” approach is a notion of what the underlying media is about . Just like the last company a few Canopy employees were involved in, we believe strongly in learning as much about the underlying content as we do matching peoples’ interactions against each other. We have already built a suite of content analysis approaches that can also find the inherent similarities between lots of types of content. This lets us unpack the model with more underlying understanding of the why : “you enjoyed something about whales, and we figured you may want to watch this documentary about nature.” It also helps us prioritize niche content: finding underserved types of discoveries.
Our strong belief in content, explainability and recourse comes to a fine point with the announcement of one of our first hires -- Bassey Etim , who ran the NY Times’ community desk for many years. Bassey’s role is to build a team to be the voice of Canopy, help the various systems get better at learning how different stories interrelate, help guide our content analysis systems, and give crucial context to any sort of recommendation. A future in which Canopy is mediating the worlds’ discovery starts with us ensuring our results reflect humanity.
We’re really excited to show off how we’ve re-thought this crucial part of your daily experience, to put you back in the center and get the world re-focused on discovering great things. There are so many exciting new experiences that can happen when you’ve got a great discovery platform that you can trust. We’re just getting started.