How music recommendation works -- and doesn't work
When you see an automated music recommendation do you assume that some stupid computer program was trying to trick you into something? It’s often what it feels like – with what little context you get with a suggestion on top of the postmodern insanity of a computer understanding how should you feel about music – and of course sometimes you actually are being tricked.
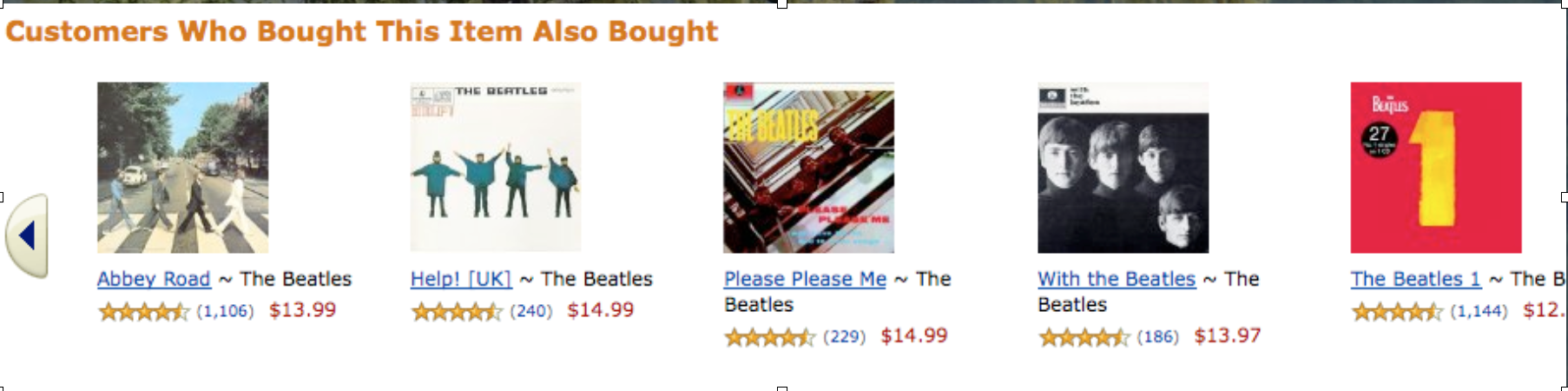
Amazon’s recommendations for Abbey Road
No one is just learning that if they like a Beatles album, they may also like five others. Amazon is not optimizing for the noble work of raising independent artists’ profiles to the public, and they’re definitely not optimizing for a good musical experience. They’re statistically optimizing to make more money, to sell you more things. Luckily this is the fruit fly of music recommendation, the late night infomercial quality of a music discovery experience that also might dry your lettuce if you spin it fast enough. And I doubt Amazon would ever claim otherwise.
The rest of the field has gotten pretty far since then and we’ve now got tons of ways to discover music using actual qualities of the music or social cues of what your friends are listening to. But I still hate seeing examples like the above. I hate thinking there are forces at work in music discovery that don’t have listeners’ best interests at heart and I want to make them better. I want to walk through all the ways music recommenders work or don’t, and concentrate of course on the one I know best – The Echo Nest’s – which you’re probably using even if you don’t already know it. And most importantly, I want to talk about what we can do next.
Before I get into it, a brief history of who I am: I’ve been working on music recommenders and music retrieval since 1999, academically and in industry. In 2005 I started The Echo Nest with my co-founder Tristan. We power most online music services’ discovery using a very interesting series of algorithms that is sort of the Voltron-figure of our two dissertations and the hard work of our 50 employees in Boston, SF, NYC and London. And we’ve been on a bit of a tear – just in the past year alone we’ve announced that we’re powering music discovery features for eMusic, Twitter, EMI, iHeartRadio, Rdio, Spotify, VEVO and Nokia – with some new heavy hitters yet announced – to add to our existing customer base that includes MTV, MOG, and the BBC. And through our API we have tens of thousands of developers making independent apps like Discovr, KCRW, Muzine, Raditaz, Swarm, SpotON and hundreds more.
We’ve been a quiet company for a while and with all this great news comes a lot of new confusion about what we do and how it compares to other technologies. Journalists like to pin us as the “machine” approach to understanding music next to the “human” of our nearest corollary (not competitor) in the space – Pandora. This is somewhat unfair and belies the complexity of the problem. Yes, we use computer programs to help manage the mountains of music data, but so does everyone, and the way we get and use that data is just as human as anything else out there.
I’ll go into technologies like collaborative filtering, automatic content based recommendation, and manual approaches used by Pandora or All Music Guide (Rovi). I’ll show that no matter what the computational approach ends up being, the source data – how it knows about music – is the most important asset in creating a reliable useful music discovery service.
What is recommendation? What is it good for?
Musicians are competing for an audience among millions of others trying just as hard. And it’s not the listener’s fault if they miss out on something that will change their lives – these days, anyone can gain access to a library of over 15 million songs on demand for free. To a musician turned computer scientist (as I and so many of my colleagues are) this is the ultimate hidden variable problem. If there was something “intelligent” that could predict a song or artist to a person, both sides (musician and listener) win, music is amazing, there’s a ton of data, and it’s very far from solved.
But anyone in the entire field of music technology has to treat music discovery with respect: it’s not about the revenue of the content owner, it’s not about the technology, it’s not about click through rates, listening hours or conversion. The past few years have shown us over and over that filters and guides are invaluable for music itself to coexist with the new ways of getting at it. We track over 2 million artists now – I estimate there are truly 50 million, most of them currently active. Every single one of them deserves a chance to get their art heard. And while we can laugh when Amazon suggests you put a Norah Jones CD in your cart after you buy a leaf blower, the millions of people that idly put on Pandora at work and get excited about a new band they’ve never heard deserve a careful look. Recommendation technology is powering the new radio and we have a chance to make it valuable for more than just the top 5 percent of musicians.
When people talk about “music recommendation” or “music discovery” they usually mean one of a few things:
- Artist or song similarity: an anonymous list of similar items to your query. You can see this on almost any music service. Without any context, this is just a suggestion of what other artists or songs are similar to the one you are looking at. Formally, this is not truly a recommendation as there is no user model involved (although since a query took the user to the list, I still call these a recommendation. It’s a recommendation in the sense that a web search result is.)
- Personalized recommendation: Given a “user model” (your activity on a service – plays, skips, ratings, purchases) a list of songs or artists that the service does not think you know about yet that fits your profile.
- Playlist generation: Most consumers of music discovery are using some form of playlist generation. This is different from the above two in that they receive a list of items in some order (usually meant to be listened to at the time.) The playlist can be personalized (from a user model) or not, and it can be within catalog (your own music, ala iTunes Genius’s or Google’s Instant Mix playlists) or not (Pandora, Spotify’s or Rdio’s radio, iHeartRadio.) The playlist should vary artists and types of songs as it progresses, and many rely on some form of steering or feedback (thumbs up, skips, etc.)
Where popular services sit in discovery
| Personalized | Anonymous | |
|---|---|---|
| Playlist | Pandora | Rdio radio |
| Suggestions | Amazon | All Music Guide |
These are three very different ways of doing music discovery, but for every technology and approach I know of, they are simply applications on top of the core data presented in different ways. For example, at the Echo Nest we do quite a bit to make our playlists “radio-like” using our observed statistics, acoustic features and a lot of QA but that sort of work is outside the scope of this article – all three of our similarity API, taste profiles (personalized recommendation) API and playlist API start with the same knowledge base culled from acoustic and text analysis of music.
However, the application means a lot to the listener. People seem to love playlists and radio-style experiences, even if the data driving both that and the boring list of songs to check out are the same. One of the great things about working at the Echo Nest is seeing the amazing user interfaces and experiences and people put on top of our data. Listeners want to hear music, and they want to trust the service and have fun doing it. And conversely, a Pandora completely powered by Echo Nest data would feel the same to users but would have far better scale and results and thus add to the experience. Because of this very welcome sharding of discovery applications, it’s helpful less to talk about these applications directly and more to talk about “what the services know” about music – how they got to the result that Kreayshawn and Uffie are similar, no matter where it appeared in the radio station or suggestion or what user model led them there. We can leave the application and experience layer to another lengthy blog post.
My (highly educated, but please know I have no direct inside information except for Echo Nest of course) guesses on the data sources are:
How popular services know about music
| Service | Source of data |
|---|---|
| Pandora | Musicologists take surveys |
| Songza | Editors or music fans make playlists |
| Last.fm | Activity data, tags on artists and songs, acoustic analysis (1) |
| All music guide | Music editors & writers |
| Amazon | Purchase & browsing history |
| iTunes Genius | Purchase data, activity data from iTunes (2) |
| Echo Nest | Acoustic analysis, text analysis |
There are many other discovery platforms but this list covers the widest swath of approaches. Many services you interact with use either these platforms directly (Last.fm, Echo Nest, AMG all license data or give away data through APIs) or use similar enough approaches that it’d be not worth going into in detail.
From this list we’re left with a few major music knowledge approaches: (1) activity data, (2) critical or editorial review, (3) acoustic analysis, and (4) text analysis.
The former two are self-describing: you can learn about music by the activity around it (listens, plays, purchases) – Kreayshawn and Uffie are considered similar if the same people buy their singles or rate them highly – or you can learn about music by critical review, what humans have been pretty good at for some time. Of course, encoding activity (via collaborative filtering or taste mining) and critical review (via surveys or direct entry) into a database is a relatively recent art.
The latter two, acoustic and textual analysis, were developed by the field as a reaction to the failures of the first two. I’ll go into much greater detail on those as it’s how Echo Nest does its magic.
Care and Scale
The dominating principle of the Echo Nest discovery approach from day one has been “care and scale.” When Tristan and I started the company in 2005 we were two guys with fresh PhDs on music analysis and some pretty good technological solutions; Tristan’s in the acoustic analysis realm (a computer taking a signal and making sense of it) and mine in the data mining and language analysis space (understanding what people are saying and doing with music.) We surveyed the landscape at the time for discovery and found that almost every one suffered from either a lack of care or scale, sometimes (and often) both. The entire impetus of doing a startup (not an easy choice for two scientists and anyone that has met us knows we are not the “startup type”) was that we thought we had something between the two of us that could fix those two problems.
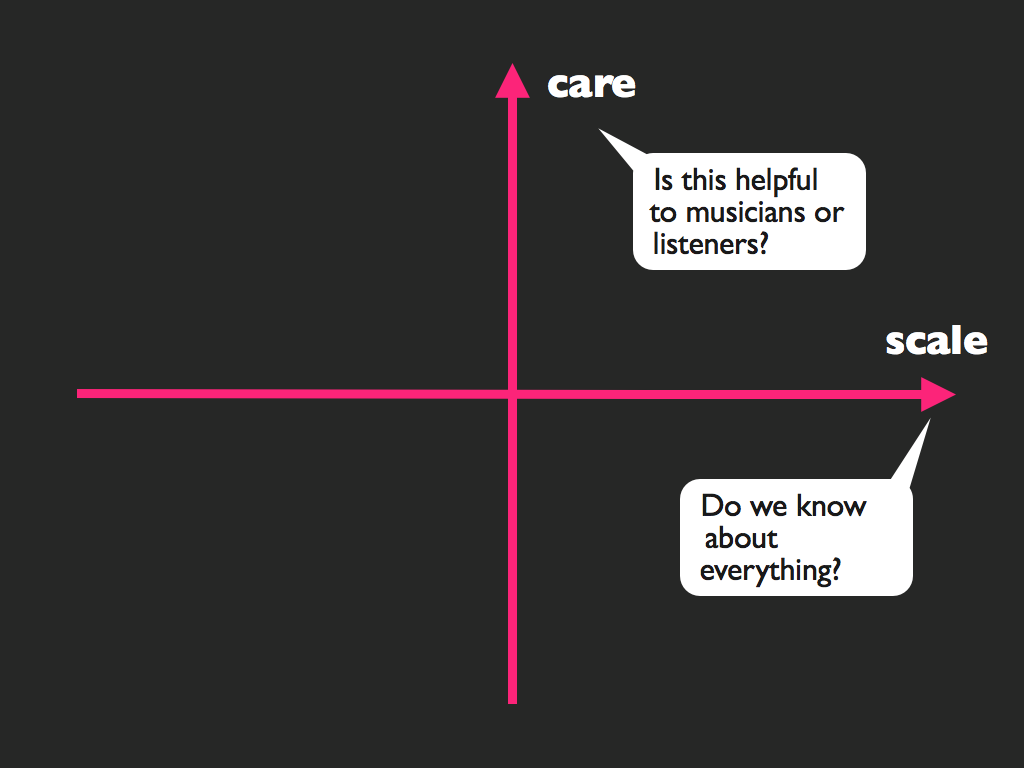
Care & Scale
Scale is easy to explain: you have to know about as much music as possible to make good recommendations. If you don’t know about an up and coming artist, you can’t recommend them. If you only analyze or rate or understand the popular stuff you by default fail at discovery. Manual discovery approaches by their nature do not scale. We track over two million artists and over 30 million songs and there is no way a manually curated database can reach that level of knowledge. Even websites that can be volunteer or community edited run against the limits of the community that takes part – we count only a little over 130,000 artist pages on Wikipedia. Pandora recently crossed the 1 million song barrier, and it took them 10 years to get there. Try any hot new artist in Pandora and you’ll get the dreaded:
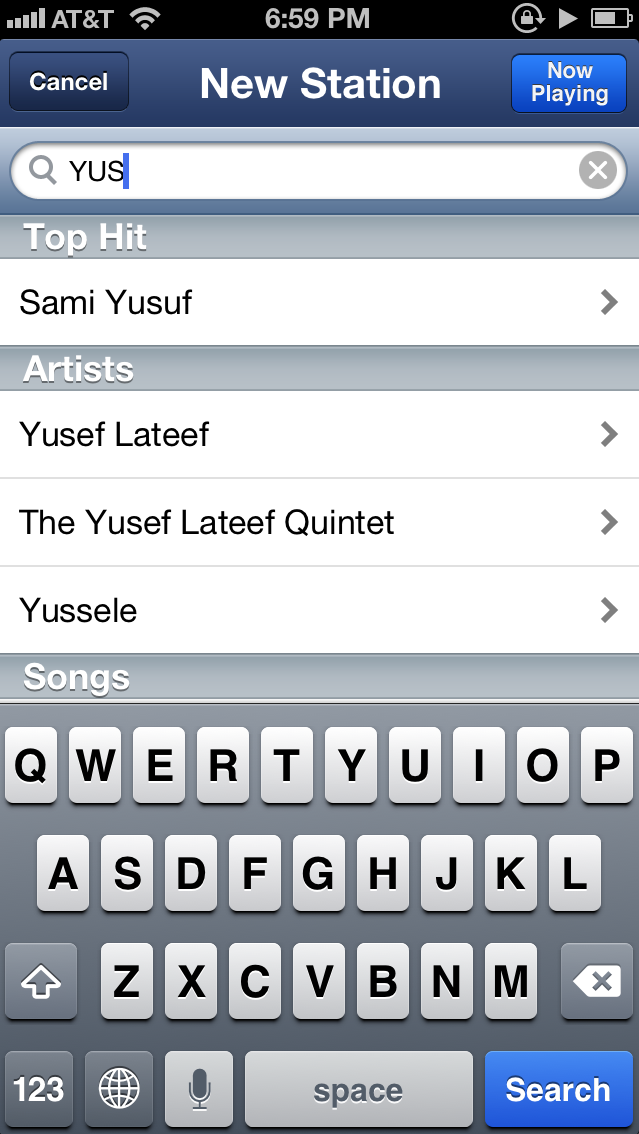
Pandora not knowing about YUS
This is Pandora showing its lack of scale. They won’t have any information for YUS for some time and may never unless the artist sells well. This is bad news and should make you angry: why would you let a third party act as a filter on top of your very personal experiences with music? Why would you ever use something that “hid” things from you?
Activity data approaches (such as Last.fm and Amazon and iTunes Genius) also suffer from a slighter scale problem that manifests itself in a different way. It’s trivial to load a database of music into an activity data-based discovery engine (such as collaborative filtering or social tags.) I’ve often gone after such naive approaches to music discovery publicly. If a website or store has a list of user data (user A bought / listened to song Y at time Z) any bright engineer will immediately go into optimization mode. There’s almost a duplicitous ease of recommending music to people poorly. I recently was shopping for a specific type of transistor for a project on a parts and components website and found they, too, had turned on the SQL join that allowed “recommendations” on their site based on activity data:
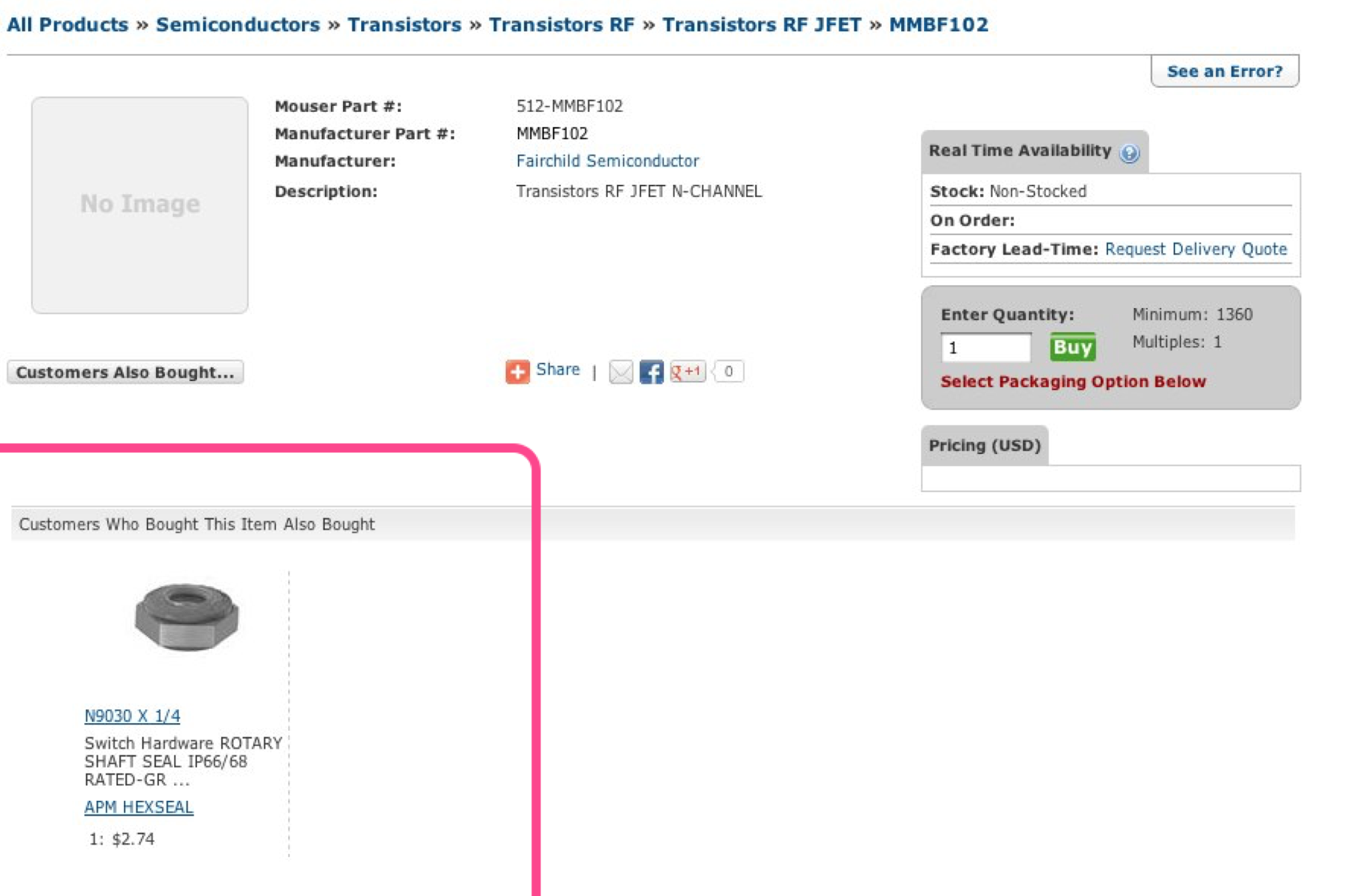
Pathological filtering
Other than activity not making much sense in a discovery context, by default these systems suffer a “popularity bias,” where a lot of music simply doesn’t have enough activity data yet collected to be considered a recommendation match. Activity based systems can only know what people have told them explicitly, and this often makes it hard for less-popular artists to be recommended.
Care is a trickier concept and one we’ve tried very hard to define and encode into our engineering and product. I translate it as “is this useful for the musician or listener?” A great litmus test for care in music discovery is to check the similar artists or songs to The Beatles. Is it just the members of the Beatles and their side projects? For almost all services that use musical activity data, it will be:
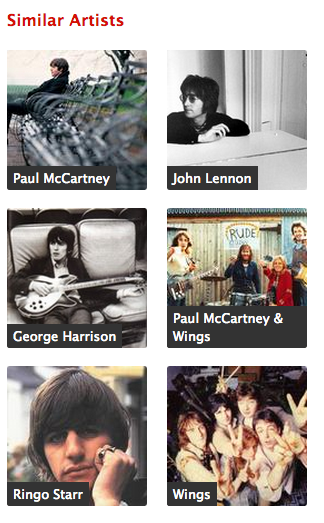
Top artist similars are all members of the Beatles
Certainly a statistically correct result (3), but not a musically informative one. There is so much that user data can tell you about listening habits, but blindly using it to inform discovery belies a lack of care about the final result. Care is neatly handled by using social, manual or editorial approaches, as humans are pretty good at treating music properly. But when using more statistical or signal processing approaches that know about more music at scale, care has to be factored in somehow. Most purely signal processing approaches (such as Mufin here) fall down as badly on care as activity data approaches do:
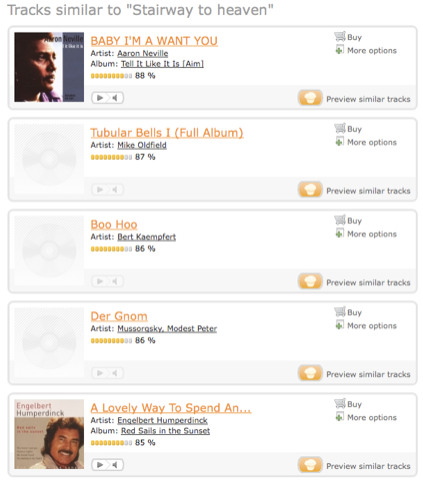
Mufin expressing so little care about Stairway to Heaven
Care is a layer of quality assurance, editing and sanity checks, real-world usage and analysis and, well, care, on top of any systematic results. You have to be able to stand by your results and fix them if they aren’t useful to either musicians or listeners. Your WTF count has to be as low as possible. We’ve spent a lot of time embedding care into our process and while we’re always still working, we’re generally pleased with how our results look.
Without both care and scale you’ve got a system that a listener can’t trust and that musician can’t use to find new fans. You’ve failed both of your intended audiences and you might as well not try at all.
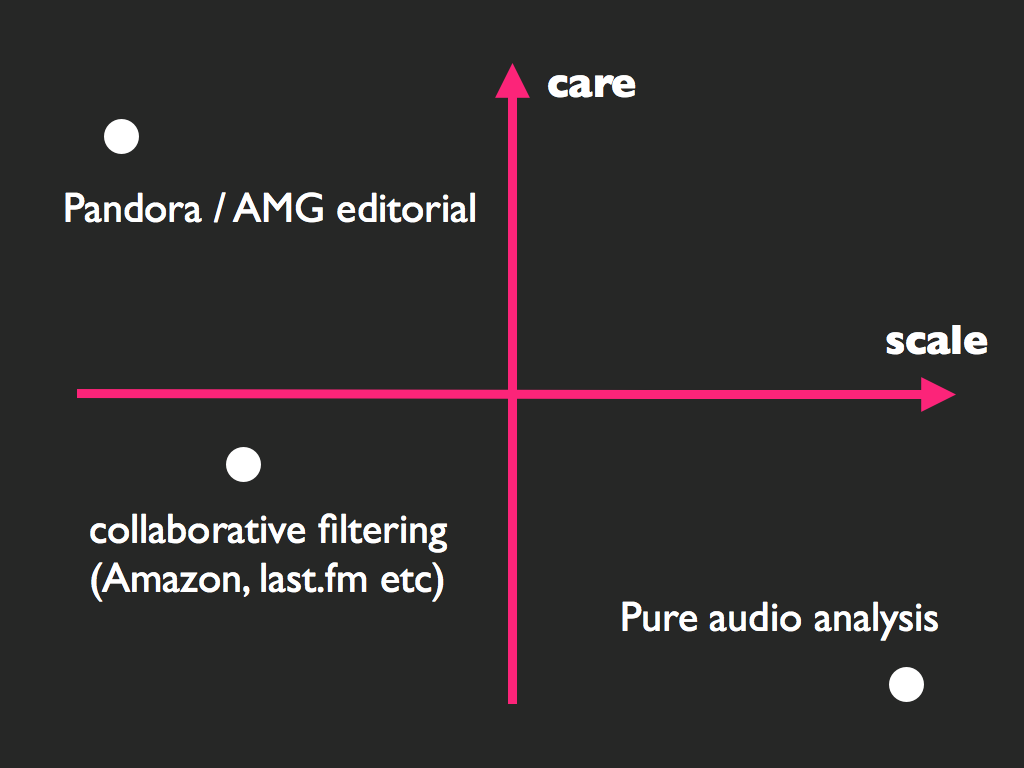
Care & Scale of common approaches
Text Analysis
Echo Nest Cultural vectors
I started doing music analysis work in 1999 at the NEC Research Institute in Princeton, NJ (I had scammed them into an internship and then a full time job by being very persistent.) NEC was then full of the top tier of data mining, text retrieval, machine learning and natural language processing (NLP) (4) scientists; I had the great fortune to work with guys like Steve Lawrence, Gary Flake, David Waltz and even Vladimir Vapnik moved into my tiny office after I left for MIT.
I was there while figuring out what to do with myself after abruptly quitting my PhD program in NLP at Columbia. I was a musician at the time, playing a lot of shows at various warehouse spaces or the lamented late “Brownies,” places where 20 people might show up and 10 would know who you were. There was a lot of excitement about “the future of music” – far more than there is today, as somehow we felt that the right forces would win and quickly. I logged onto Napster for the first time from a DSL connection and practically squealed in delight as a song could be downloaded faster than the time it would take to listen to it. It was a turning point for music access, but probably a step back for music discovery. We were still stuck with this:
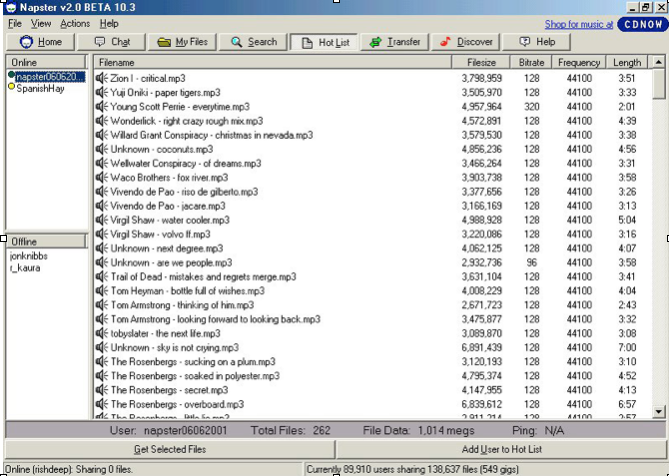
Napster in 2001
The search was abysmal: a substring match on ID3v1 tags (32 characters each for artist, title, release and a single byte for genre) or filename (usually “C:MUSICMYAWES~1RAPSONG.MP3”) and there was no discovery beyond clicking on other users’ names and seeing what they had on their hard drives. I would make my music available but of course, no one would ever download it because there was no way for them to find it. A fellow musician friend quickly took to falsely renaming his songs as “remixes” by better known versions of himself: “ARTIST - TITLE - APHEX TWIN MIX” and reported immediate success.
At the time I was a member of various music mailing lists, USENET groups and frequent visitor of a new thing called “weblogs” and music news and review sites. I would read these voraciously and try to find stuff based on what people were talking about. To me, while listening to music is intensely private (almost always with headphones alone somewhere), the discovery of it is necessarily social. I figured there must be a way to take advantage of all of this conversation, all the excited people talking about music in the hopes that others can share in their discovery – and automate the process. Could a computer ‘read’ all that was going on across the internet? If just one person wrote about my music on some obscure corner of the web, then the system could know that too.
This is scale with care: real people feeding information into a large automated system from all different sources, without having to fill out a survey or edit a wiki page or join a social network.
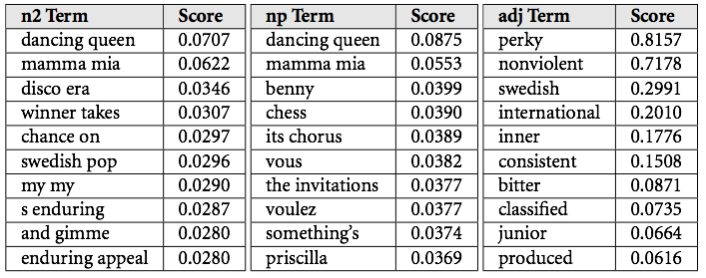
After almost ten years of data mining, language and music research (first at NECI, then a PhD at MIT at the Media Lab) The Echo Nest currently is the only music understanding service that takes this approach. And it works. We crawl the web constantly, scanning over 10 million music related pages a day. We throw away spam and non-music related content through filtering, we try to quickly find artist names in large amounts of text and parse the language around the name. Every word anyone utters on the internet about music goes through our systems that look for descriptive terms, noun phrases and other text and those terms bucket up into what we call “cultural vectors” or “top terms.” Each artist and song has thousands of daily changing top terms. Each term has a weight associated, which tells us how important the description is (roughly, the probability that someone will describe music as that term.) We don’t use a fixed dictionary for this, we are able to understand new music terms as quickly as they are uttered, and our system works in many Latin-derived languages across many cultures.
On top of this statistical NLP, we also pull in structured data from a number of partners and community access sites like Wikipedia or Musicbrainz. We apply the same frequency and vector approach to this knowledge-base style data: if Wikipedia lists the location of an artist as NYC and the label partner as New York, NY and their Facebook page has “EVERYWHERE ON TOUR 2012”, we have to figure out which is the right answer to index. Often the cultural vectors on structured data become a synthesis of all the different data sources.
When a query for a similar artist or a playlist comes into our system, we take the source artist or song, grab its cultural vectors, and use those in real time to find the closest match. This is not easy to do at scale, and over the years we’ve done quite a lot of “big data” work to make this tractable. We don’t cache this data because it changes so often – the global conversation around music is very finicky and artists make overnight changes to their sound.
A lot of useful data naturally falls out of cultural analysis of music: the quantity of conversation is used to inform our “hotttnesss” and familiarity data points, representing how popular the artist is now on the internet and overall how well known they might be. We can use the crawled text anonymously as sort of a proxy for listener data without having to get it from a playback service. And the index of documents that relate to artists or songs is of course valuable to a lot of our customers in a feed or search context – showing news or reviews about artists their users are interested in.
Acoustic Analysis
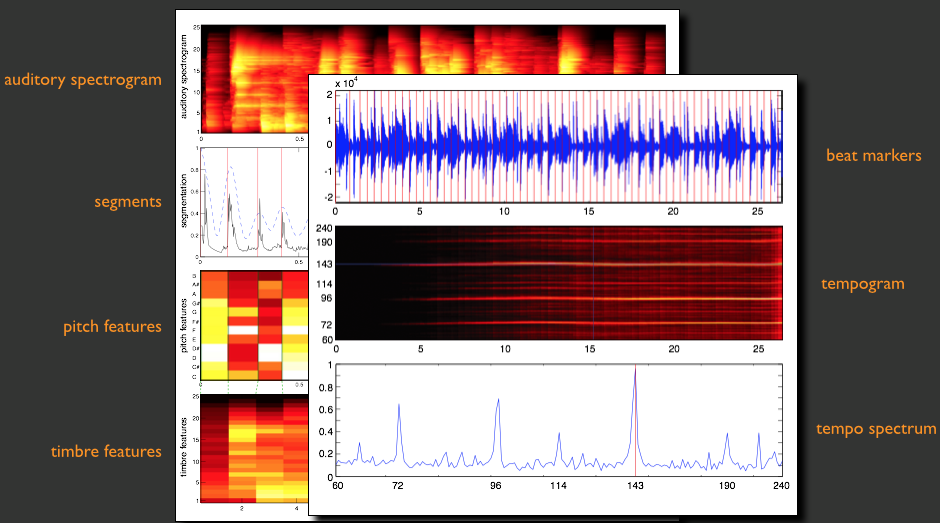
Echo Nest acoustic analysis view
The internet is not the Library of Babel we envision it to be, and quite often many “lower-rank” (less popular) musicians are left out of the “cultural universe” we crawl. Also, the description of music necessarily leaves out things that actually describe the music – a Google blog search for Rihanna illustrates the problem well: many popular artists’ descriptions are skewed towards the celebrity angle and while this is certainly a valid thing to know about a musician, it’s not all we need to know. Lastly, internet discussion of music tends to concentrate on artists, not songs (although there is sometimes talk of individual songs on music blogs.) These three issues (and common sense) require us figure out if we can understand how a song sounds as well as how the artist and song is represented by listeners. And if we are going to follow care and scale, we’ve got to do this automatically, with a computer doing the job of the careful listening.
Can a computer really listen to music? A lot of people have promised it can over the years, but I’ve (personally) never heard a fully automated recommendation based purely on acoustic analysis that made any sense – and I’ve heard them all, from academic papers to startups to our own technology to big-company efforts. And that has a lot to do with the expectations of the listener. There are certain things computers are very good and fast at doing with music, like determining the tempo or key, or how loud it is. Then there are harder things that will get better as the science evolves, like time signature detection, beat tracking over time, transcription of a dominant melody, and instrument recognition. But even if a computer were to predict all of these features accurately, does that information really translate into a good recommendation? Usually not – and we’ve shown over the years that people’s expectation of “similar” – either in a playlist or a list of artists or songs – trends heavily towards the cultural side, something that no computer can get at simply by analyzing a signal.
But it does turn out that acoustic analysis has a huge part to play in our algorithms. People expect playlists to be smooth and not jump around too much. Quiet songs should not be followed with loud metal benders (unless the listener asked for that.) For jogging, the tempo should steadily increase. Most coherent mixes should keep the instrumentation generally stable. Songs should flow into one another like a DJ would program them, keeping tempo or key consistent. And there’s a ton we haven’t figured out yet on the interface side. Could a “super dorky query interface” work for music recommendation, where a listener can filter by dominant key or loudness dynamics? Maybe with the right user experience. An early product out of the Echo Nest (5) was an “intelligent pause button” that Tristan whipped up that would compose a repeating segment out of the part of the song you were in or just play the song roughly forever (check out an automated 10 minute MP3 re-edit of a Phoenix song) – which a few years later became Paul’s amazing Infinite Jukebox – these experiments are fascinating precursors to a new listening experience that might become more important than discovery itself.
The Echo Nest audio analysis engine (PDF) contains a suite of machine listening processes that can take any audio file and outputs both low-level (such as the time of when every beat starts) and high-level (such as the overall “danceability”) information for any song in the world. We analyze all the music we work with, and developers can upload their own audio to see everything we compute on a track via our API. Our analysis starts by pretending it was an ear: it will model the frequencies and loudness of a musical signal much the same way perceptual codecs like MP3 or AAC do. It then segments the audio into small pieces – roughly 200ms to 4s, depending on how fast things are happening in the song. For each segment we can tell you the pitch (in a 12-dimensional vector called chroma), the loudness (in an ADSR-style envelope) and the timbre, which is another 12 dimensional vector that represents the sound of the sound – what instruments there are, how noisy it is, etc. It also tracks beats across the signal, in subdivisions of the musical meter called tatums, and then per beat and bar, alongside larger song-level structure we call sections that denote choruses, intros, bridges and verses.
That low level information can be combined through some useful applications of machine learning that Tristan and has team have built over the years to “understand” the song at a higher level. We emit song attributes such as danceability, energy, key, liveness, and speechiness, which aim to represent the aboutness of the song in single floating point scalars. These attributes are either heuristically or statistically observed from large testbeds: we work with musicians to label large swaths of ground truth audio against which to test and evaluate our models. Our audio analysis can be seen as an automated lead sheet or a computationally understandable overview of the song: how fast it is, how loud it gets, what instruments are in it. The data within the analysis is so fine grained that you can use it as a remix tool – it can chop up songs by individual segments or beats and rearrange them without anyone noticing.
We don’t use either type of data alone to do recommendations. We always filter the world of music through the cultural approaches I showed above and then use the acoustic information to order or sort the results by song. A great test of a music recommender is to see how it deals with heavy metal ballads – you normally would expect other ballads by heavy metal bands. This requires a combination of the acoustic and cultural analysis working in concert. The acoustic information is obviously also useful for playlist generation and ordering, or keeping the mood of a recommendation list coherent.
What’s next
I’ve used every single automated music recommendation platform, technology or service. It’s obviously part of my job and it’s been astounding to watch the field (both academically and commercially) mature and test new approaches. We’ve come a long way from RINGO and while the Echo Nest-style system is undoubtedly the top of the pack these days as far as raw quality of automated results go, there’s still quite a lot of room to grow. I’ve been noticing two trends in the space that will certainly heat up in the years to come:
Social – filtering collaborative filtering
This is my jam
Social music discovery as embodied by some of my favorite music services such as This is my jam, Swarm.fm, Facebook’s music activity ticker and real time broadcasting services like the old Listening Room and its modern progentior Turntable.fm often have no or little automated music discovery. Friend-to-friend music recommendations enabled by social networks are extremely valuable in music discovery (and I personally rely on them quite often), but are not recommendation engines as they can not automatically predict anything when bereft of explicit social signals (and so they fail on scale.) The main amazing and useful feature of recommendation systems are that it can find things for you that you wouldn’t have otherwise come across.
Even though that puts this kind of service outside the scope of this article, that doesn’t mean we should ignore the power of social recommendations. There’s something very obvious in the social fabric of these services that makes personal recommendations more valuable: people don’t like computers telling them what to do.
There are some interesting new services that mix both the social aspects of recommendation with automated measures. This is my jam’s “related jams” is a first useful crack at this, as is Spotify’s recent “Discover” feature. You can almost see these as extensions of your social graph: if your friends haven’t yet caught onto Frank Ocean there might be signals that show they will get there soon, and using cultural filtering can get us there. And a lot of the power of social recommendations – that it comes from your friends – can tell the story better than just a raw list of “artists we think you would like.”
Listener intelligence
When do you listen to music? Is it in the morning on your way to work? Is it on the weekends, relaxing at home? When you do it, how often do you listen to albums versus individual songs in a playlist? Do you idly turn on an automated radio station, or have your own playlists? Which services do you use and why? If it’s raining, do you find yourself putting on different music? The scariest thing about all the music recommendation systems I’ve gone over (including ours as of right now) is none of them look at this necessary listener context.
There is a lot going on in this space, both internal stuff we can’t announce yet at Echo Nest, and new products I’m seeing coming out of Spotify and Facebook. We’re throwing our weight behind the taste profile – the API that represents musical activity on our servers. It’s sort of the scrobble 2.0: both representing playback activity as well as all the necessary context around it: your behaviors and patterns, your collection, your usage across services and maybe even domains. We’re even publishing APIs to do bulk analysis of the activity to surface attributes like “mainstreamness” or “taste-freeze,” the average active year of your favorite artists. This is more than activity mining as collaborative filtering sees it: it’s understanding everything about the listener we can, well beyond just making a prediction of taste based on purchase or streaming activity. All of these attributes and analysis might be part of the final frontier of music recommendation: understanding enough to really understand the music and the listener it’s directed to.
– Brian (brian@echonest.com)
Thanks to EVB for the edits
-
I know they do a ton of acoustic analysis there but I don’t know if it’s used in radio or similar artists/songs. Probably. ↩
-
They use Gracenote’s CDDB data as well but I don’t know to what extent it appears in Genius. ↩
-
You can even claim that since you are listening to the Beatles, you are also listening to the individual members at the same time but let’s not get too ahead of the curve here ↩
-
Whenever I say NLP I mean the real NLP, the natural language processing NLP, not the creepy pseudoscience one. ↩
-
Released eventually as the Earworm example in Echo Nest Remix. ↩